Explore Resources
Loading...

Claude Code가 돌리는 셀프호스팅 개인 위키. URL만 붙이면 그 뒤 수집이 자동화되고, `/ingest`가 날것의 메모를 서로 연결된 작은 노트로 정리하고, LanceDB 벡터 색인이 전체를 검색 가능하게 만들고, `/brief`는 관련 노트와 그 연결관계까지 모아 내가 수집해온 방향을 닮은 초안을 써줍니다.
누구나 개인 위키를 만들 순 있지만, 100개·1000개의 노트가 쌓여도 무너지지 않으려면 방법이 정해져 있어요. 의지가 아니라 두 가지 마찰을 없애는 거예요 — 수집의 번거로움, 그리고 '정리'의 비용. Second Brain(Slow AI)은 둘 다 Claude Code에 맡깁니다. [편의성] 수집은 무조건 3초컷이어야 해요. 저장하고 싶은 URL을 `/jina-capture`에 던지면 깔끔한 마크다운으로 `wiki/raw/`에 저장됩니다. 무엇을 모으느냐가 당신의 taste를 결정짓는 첫 단계예요. 더 중요한 건 가장 공수가 큰 부분을 제거하는 것 — 새 노트가 기존 수백 개의 노트와 어떻게 연결되는지를 `/ingest`가 raw를 읽고 알아서 연결된 노트로 만들어 줍니다. [확장 가능성] 이걸 지속 가능하게 받쳐주는 숨은 기능이 둘 있어요. 하나는 Zettelkasten처럼 노트를 작은 개념으로 잘게 쪼개는 것 — 한 노트에 개념이 다섯 개 엉켜 있으면 깔끔하게 연결되기 힘드니까요. 다른 하나는 LanceDB 벡터 저장소, 즉 개인 위키 전용 RAG로 관련 자료를 기억에 의존하지 않고 자동으로 찾아내는 것. [그래서] 보상은 `/brief`예요. 주제만 던지면 관련 노트뿐 아니라 느슨하게 연결된 이웃 노트까지 모아 초안을 만들어, 단일 출처 요약이 아니라 내가 그동안 축적해온 방향성을 닮은 글이 나옵니다. 무엇을 모았고 어떻게 엮었는지가 곧 개인의 taste가 되는 거죠.
링크와 메모를 계속 저장하지만 다시 안 들춰보는 더미로 썩어갈 때, 그리고 노트가 늘수록 더 감당 안 되는 게 아니라 더 촘촘히 연결되는 위키를 원할 때. Claude Code를 이미 쓰고 있다면 best — 턴키 GUI 앱을 원하면 덜 맞아요. 로컬에서 직접 돌리는 레포입니다.
세팅이 제일 쉬워요 — 따라 할 단계 같은 거 없습니다. 레포 URL을 Claude Code에 보내고 "이걸 내 디렉터리에 구현해줘"라고만 하면 알아서 프로젝트를 깔아줘요. 그 뒤로는 전부 슬래시 명령어로 씁니다. `/jina-capture <url>`로 수집, `/ingest`로 raw를 연결된 노트로 정리, `/ask`로 노트 질의, `/brief <주제>`로 문서 초안, `/garden`으로 주간 정리.
~30 min to set up, then seconds per capture

자연어 프롬프트를 바로 쓸 수 있는 Lottie 애니메이션으로 바꿔주는 오픈소스 스킬. 움직임을 말로 설명하고 SVG를 가리키면 에이전트가 Lottie JSON을 써주고 — 내장 플레이어로 타임라인을 넘기고 속성을 만지고 내보내기까지, After Effects 없이 끝납니다.
Lottie는 벡터 애니메이션을 웹·iOS·안드로이드·React Native·Flutter로 내보내는 표준 포맷이지만, 만들려면 보통 After Effects에 Bodymovin 플러그인을 붙이거나 빽빽한 JSON 키프레임을 손으로 고쳐야 했어요. Text-to-Lottie(Diffusion Studio)는 그 작업을 코딩 에이전트로 우회시킵니다. 스킬로 설치(`npx skills add diffusionstudio/lottie`)한 뒤 Claude Code나 Codex에 평범한 말로 — '이 로고를 펄스로, ease-in-out, 반복' — SVG나 스크린샷, 실제 데이터를 소스로 가리키며 프롬프트하면 됩니다. 에이전트가 Lottie JSON을 뱉고, 함께 들어 있는 플레이어가 그걸 실시간으로 렌더링해서 타임라인을 스크럽하고 노출된 컨트롤(로고 색, 선 두께, 기본 배경색)을 미리보기 안에서 바로 조정할 수 있어요. 결과물은 앱에 그대로 떨어뜨리거나 After Effects에서 마지막 손질을 할 수 있는 순수 `.lottie`/JSON입니다. 흥미로운 지점은 모션 디자인을 '손으로 키프레임 찍는 것'이 아니라 '에이전트가 쓰고 내가 검수하는 것'으로 다룬다는 거예요 — 플레이어가 그걸 정직하게 잡아줍니다. JSON이 아니라 실제 움직임을 보게 되니까요.
웹이나 모바일 UI에 쓸 Lottie 애니메이션이 필요한데 After Effects는 열기 싫을 때 — 또는 SVG 로고가 있고 어떤 움직임을 원하는지 분명해서 애니메이션과 내보내기만 맡기고 싶을 때. 복잡한 캐릭터 애니메이션이나, 처음부터 프레임 단위로 손수 제어해야 하는 작업에는 덜 맞습니다.
`npx skills add diffusionstudio/lottie`로 스킬을 설치한 뒤, 에이전트(Claude Code·Codex)에 애니메이션을 설명하고 SVG·스크린샷·데이터를 가리키며 프롬프트하세요. 'ease-in-out' 같은 모션 용어를 쓰고, 길이·fps를 지정하고, 기본 배경색 외에 원하는 커스텀 컨트롤이 있으면 명시적으로 요청하세요. 내장 플레이어에서 미리보고 다듬은 뒤 JSON을 내보내거나, After Effects에서 마저 손질하면 됩니다.
minutes to install, an hour to dial in one animation
두 PDF를 사람 눈으로 보듯 페이지별로 비교해요. 한 파일을 다른 파일 위에 겹쳐 놓고 달라 보이는 부분을 표시해주니, 뭐가 바뀌었는지 한눈에 잡힙니다.
diff-pdf가 답하는 질문은 하나예요. 이 두 PDF가 똑같아 보이나요? 속의 텍스트를 비교하는 게 아니라, 화면에 실제로 보이는 모습을 비교합니다. 두 파일을 페이지별로 나란히 맞춰 겹친 뒤, 일치하지 않는 자리를 전부 표시해줘요. 그래서 줄이 밀렸거나, 그림이 바뀌었거나, 글꼴이 다르게 찍힌 부분이 바로 눈에 띕니다. '뭔가 바뀌었나?' 싶은 순간에 딱이에요. 보고서를 다시 뽑았거나, 인보이스를 재출력했거나, 문서를 만드는 도구를 업그레이드한 뒤에 새 버전이 예전과 똑같아 보이는지 확인하고 싶을 때요. 작고 무료인(GPL-2.0) 명령줄 도구이고, PDF 내용을 읽거나 이해하지는 않아요. 그저 각 페이지가 만들어내는 '그림'을 비교할 뿐입니다.
두 PDF가 똑같아 보이는지 확인해야 할 때. 다시 만든 문서가 원본과 여전히 일치하는지 확인하거나, 버전 사이에 생긴 의도치 않은 레이아웃 변화를 잡아내거나, 도구를 업그레이드한 뒤 출력이 조용히 바뀌지 않았는지 점검할 때요. PDF에서 텍스트나 데이터를 뽑아내는 도구는 아닙니다. 페이지를 내용이 아니라 그림으로 보거든요.
두 파일을 넘기면 끝 — `diff-pdf old.pdf new.pdf` — 다른지 아닌지 알려줘요. 옵션을 붙이면 바뀐 부분을 표시한 PDF로 저장하거나, 좌우로 나란히 띄워 한 장씩 넘기며 직접 차이를 볼 수도 있습니다. 문서를 다시 만드는 작업의 마지막 점검 단계로 쓰기 좋아요.
minutes to install and run
전문가가 떠나면 수년치 맥락도 같이 사라지죠. COLLEAGUE.SKILL은 그 사람의 실제 업무 흔적 — 채팅·문서·이메일 — 을 버전 관리되는 스킬 패키지로 증류해 AI 에이전트에 설치합니다.
보통 AI 에이전트는 당신이 프롬프트로 알려준 것만 압니다. COLLEAGUE.SKILL(상하이 AI Lab)은 한 사람이 쌓아온 업무 — 채팅 로그, 설계 문서, 이메일, 심지어 회의 자막까지 — 를 에이전트가 실행할 수 있는 설치형 스킬로 바꿉니다. 출력을 일부러 두 층으로 나눠요. 역량 층은 그 사람이 문제를 풀어가는 방식, 즉 사고 모델과 판단 기준이고, 행동 층은 말투와 지켜야 할 선입니다. '판단'과 '말투'를 분리해서, 톤은 복제하지 않고 사고만 빌려오거나 그 반대도 됩니다. 패키지는 블랙박스가 아니에요. 직접 열어 읽고, 자연어로 고치고, 코드처럼 버전을 되돌리고, Claude Code·Codex·Hermes에 두루 설치합니다. 핵심 베팅은 전문성의 이동 단위가 '스킬'이고 에이전트 호스트는 갈아 끼울 수 있다는 것.
핵심 인물이 떠나려 하거나 이미 떠났고, 그 판단이 깔끔한 문서가 아니라 흩어진 흔적 속에 남아 있을 때. 또 누군가의 사고는 빌리되 말투는 따라 하고 싶지 않을 때. 증류할 실제 흔적 자체가 없다면 효용은 떨어집니다.
채팅 로그·설계 문서·이메일·자막 같은 원시 흔적을 연결하면 스킬 패키지가 생성됩니다. 뭘 뽑아냈는지 직접 살펴보고, 자연어로 고친 뒤, 쓰는 에이전트 호스트에 설치하세요. 알아둘 점 하나 — 동료의 행동을 동의 없이 증류하는 건 이 프로젝트가 일으킨 논란의 지점이기도 합니다.
an afternoon to distill and install one skill
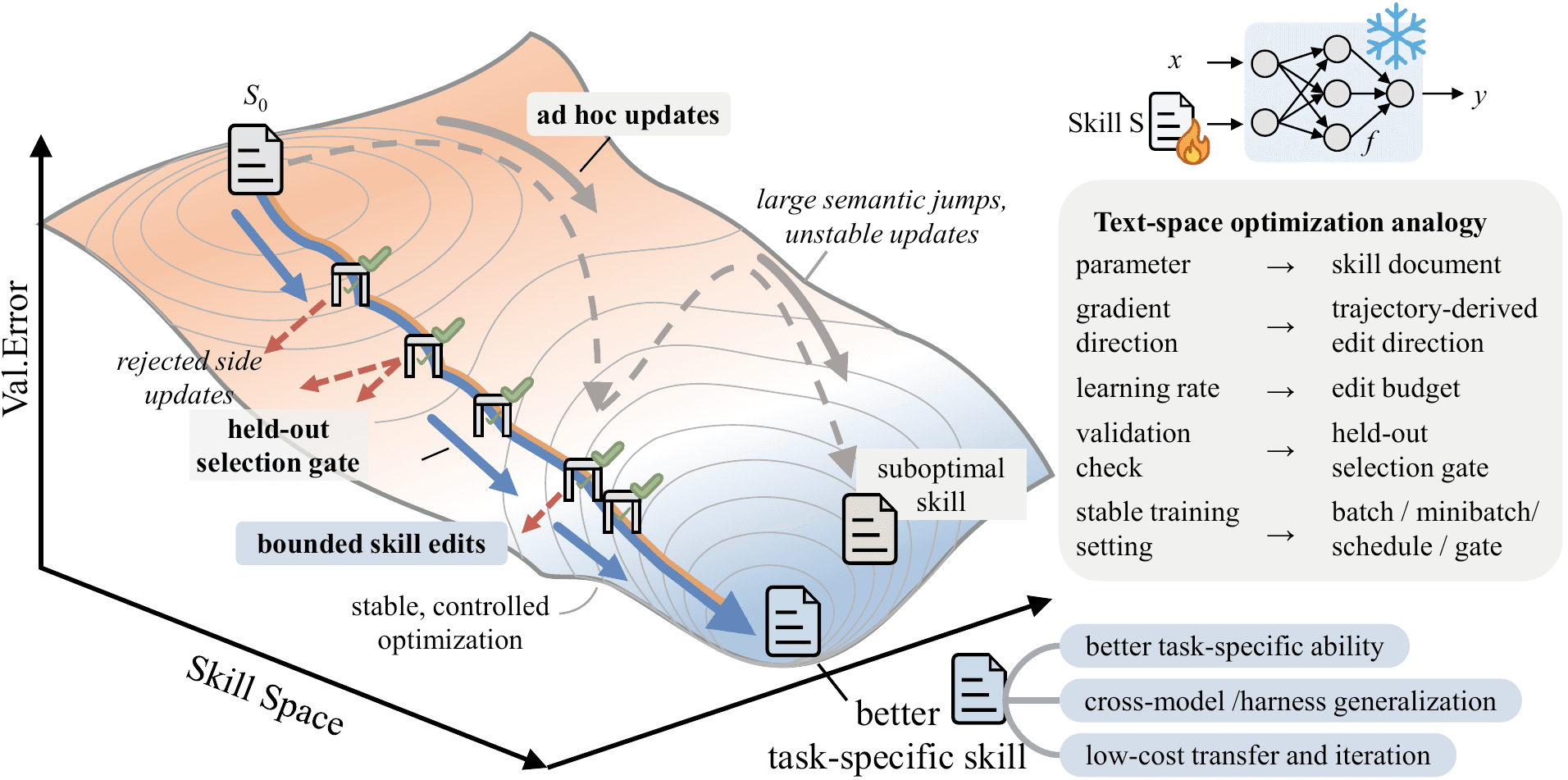
모델을 다시 학습시키지 않고 AI 에이전트를 똑똑하게. SkillOpt는 모델 대신 '설명서' 한 장을 훈련하고, 시험 점수가 실제로 오른 수정만 남겨요.
보통은 프롬프트를 손으로 고치며 감으로 개선하죠. SkillOpt는 그 과정을 자동화해요. 에이전트가 일을 해보면 별도의 '옵티마이저' 모델이 뭐가 통하고 뭐가 안 통했는지 보고, 스킬 문서의 문장을 추가·삭제·수정합니다. 핵심은 이거예요. 따로 떼어둔 데이터에서 점수가 실제로 올라야만 그 수정을 채택해서, 글이 엉뚱하게 흘러가지 않고 한 걸음씩 좋아집니다. 모델도 에이전트도 그대로고 바뀌는 건 텍스트뿐이라, 실제로 돌릴 때 추가 비용이 없어요. 정답이 분명한 작업(QA·수학·코드)에 가장 잘 맞아요.
모델은 다시 못 바꾸는데 정답을 객관적으로 채점할 수 있는 작업에서, 정확도를 공짜로 더 끌어올리고 싶을 때. 글쓰기 같은 주관적 작업에는 믿을 만한 채점기부터 만들 수 있을 때만.
`pip install skillopt` 후 내 작업에 연결하면 끝. 진짜 할 일은 라이브러리가 아니라, '이 수정이 정말 좋아진 건지' 판정할 시험(채점 기준)을 만드는 거예요.
a weekend to run a benchmark

Google이 유지보수하는 Python 라이브러리. LLM으로 비정형 텍스트에서 구조화된 필드를 뽑아냅니다. 모델이 위치를 환각하도록 두는 대신, 모든 추출을 원본의 정확한 문자 구간으로 매핑해서 — 신뢰가 아니라 검증·하이라이트·감사가 가능한 결과를 돌려줍니다.
LangExtract는 문서에서 필요한 정보를 구조화해 추출하고, 원본 텍스트의 정확한 위치에 매핑해 인터랙티브 HTML로 시각화하는 패키지입니다. 이 패키지가 성공한 이유는 사람들의 '불안 심리'를 잘 이용했기 때문이에요. 우리도 GPT가 결과를 어디에서 가져왔는지 알려주지 않으면 '진짜 맞나?' 하며 의심부터 하게 되잖아요. 그래서 어떤 정보를 추출할지 미리 정의해 주면, LLM이 관련 정보를 추출하고 — 그것들이 어디에서 나왔는지 그 근거와 함께 — 시각화까지 해 줍니다.
추출 파이프라인이 자꾸 '거의' 맞는 필드만 뽑아내고, 모든 값에 검증 가능한 영수증 — 원본의 정확한 문자 오프셋 — 이 필요할 때.
`pip install langextract` 후, 추출 지시문과 few-shot 예시를 정의하고 `lx.extract(text=..., prompt_description=..., examples=...)`를 Gemini·OpenAI·Ollama 모델 ID와 함께 호출. 결과는 `lx.visualize(...)`로 인터랙티브 HTML 뷰어를 띄워 소스 하이라이트와 함께 검토.
1 hour to wire up

LightRAG 알고리즘을 Rust로 포팅한 GraphRAG. 문서를 entity·relationship 지식 그래프로 분해하고, 쿼리는 벡터 공간과 그래프 구조를 함께 탐색합니다.
EdgeQuake는 LightRAG 알고리즘을 async Rust로 구현한 패키지 입니다. 쿼리 모드는 6가지 — naive(키워드용 벡터 검색), local(entity 중심 근방 그래프), global(커뮤니티 기반 주제형), 기본값 hybrid(local+global 결합), mix(가중치 조합), bypass(RAG 우회 LLM 직접 호출) — 각각 속도/비용을 감안해서 사용할 수 있어요. 게다가 사용하기 쉽게 웹으로도 시각화 할 수 있고, MCP 서버까지 붙어 있어서 Claude·Cursor 같은 에이전트가 직접 호출 가능합니다.
벡터 RAG가 multi-hop 추론('X와 Y가 Z를 거쳐 어떻게 연결되는가?')이나 주제형 질문에서 한계에 부딪힐 때 — production 모양의 GraphRAG 스택을 직접 짜맞추기보다 그대로 채택하고 싶을 때.
가장 빠른 길: `curl -fsSL https://raw.githubusercontent.com/raphaelmansuy/edgequake/edgequake-main/quickstart.sh | sh`. 위저드에서 OpenAI 또는 Ollama 선택 → localhost:3000 접속 → PDF drop → 만들어진 그래프를 Sigma.js 뷰에서 바로 확인.
1 hour setup

Rust 코어 문서 인텔리전스 프레임워크. 91+ 포맷에서 텍스트·OCR·코드 인텔리전스를 하나의 호출 시그니처로 추출합니다. Python에 가두는 대신, Ruby·Go·Java·Elixir 같은 언어용 네이티브 바인딩과 CLI·MCP 서버까지 함께 출하해서 어떤 에이전트 호스트든 그대로 호출할 수 있습니다.
대부분의 문서 인텔리전스 스택은 Python 강제예요. Kreuzberg는 거부합니다 — 엔진은 Rust지만 Rust·Python·Ruby·Java·Go·PHP·Elixir·C#·R·C·TypeScript(Node/Bun/WASM/Deno) 네이티브 바인딩으로 출하하고, 어느 것도 안 맞으면 CLI·REST 서버·MCP 서버로 돌릴 수 있어 어떤 에이전트 호스트든 호출 가능합니다. 출력 모양은 통일되어 있어서 — PDF든 .docx든 .epub든 .hwp든 .ipynb든 코드베이스 전체든 — 모두 하나의 `ExtractionResult`로 돌아오고 `code_intelligence`·`semantic_chunking` 필드를 포함합니다. 'RAG용 PDF' 파이프라인과 '에이전트용 코드베이스' 파이프라인이 같은 호출 시그니처를 쓴다는 뜻이에요. OCR은 Tesseract(WASM 포함)·PaddleOCR·EasyOCR·146개 제공자(GPT-4o·Claude·Gemini·Ollama·vLLM·llama.cpp)의 VLM-OCR로 갈아끼울 수 있어 — 완전 로컬에서 frontier 모델까지 설정 한 줄로 토글합니다. 베껴 쓸 만한 디자인 두 가지: 같은 페이로드를 JSON보다 30~50% 적은 토큰으로 직렬화하는 TOON 와이어 포맷, 그리고 AST 라운드트립 없이 바로 변환하는 HTML→Markdown 경로.
PDF만이 아니라 여러 문서 포맷을 다뤄야 할 때, Python 외 언어(Ruby·Go·Java·Elixir·C#)에서 더 이상 second-class 시민으로 살기 싫을 때, 한 MCP 서버에서 문서 파싱과 코드 인텔리전스를 같이 받고 싶을 때.
Python이면 `pip install kreuzberg` 후 `extract(file_path)` 한 줄. 바인딩 자체를 건너뛰려면 `npx skills add kreuzberg-dev/kreuzberg`로 에이전트 스킬을 설치 — Claude Code·Cursor·Codex가 그대로 호출합니다.
30 min to wire up

벡터 DB를 들어내고, 문서의 목차 트리를 만든 뒤 LLM이 그 트리를 직접 탐색하게 만드는 RAG. AlphaGo의 트리 탐색에서 영감을 가져왔습니다.
전문 문서(10-K 보고서, 계약서, 기술 매뉴얼)에서는 similarity ≠ relevance — 진짜 필요한 건 임베딩 기반 거리 계산이 아니라 아니라 논리적 추론입니다. PageIndex는 벡터 파이프라인 자체를 드러내고, PDF에서 계층형 목차 트리를 뽑은 뒤, 에이전트가 노드 요약을 읽고 단계마다 근거를 남기면서 트리를 따라 알맞은 정보를 찾아갑니다. 또한, 왜 특정 정보를 찾아갔는가에 대한 retrieval 근거가 쌓여 신뢰도 있는 결과물을 만들 수도 있습니다. 다만, 비용은 고려해야 합니다 — 쿼리당 LLM 호출이 최소 1번, 보통 여러 번 들어가므로 latency·비용이 올라가요. 그래도 FinanceBench에서 98.7%로 벡터 RAG를 능가하는 등 성능은 보장 된답니다.
길고 구조 있는 audit-sensitive 문서 — 재무 보고서, 계약서, 규제 PDF — 에서 벡터 RAG가 자꾸 *비슷한* 청크만 가져오고 정작 *관련 있는* 섹션은 놓칠 때.
clone → LLM 키 세팅 → `python3 run_pageindex.py --pdf_path <doc>`로 트리 빌드. 설치 자체를 건너뛰려면 pageindex.ai/developer에서 hosted API·MCP로 바로 붙이세요.
2 hours to wire up

Apache-2.0 PDF 파서. 디지털 PDF는 LLM 없이 로컬 결정론 모드로 Markdown·HTML·JSON(요소별 bbox 포함)을 그대로 뽑아냅니다. 다만 스캔본·복잡한 표·수식·차트가 섞이면, 하이브리드 AI 백엔드로 라우팅해서 OCR·수식 추출·차트 설명까지 더해줍니다.
OpenDataLoader는 MinerU·Docling·LlamaParse와 같은 자리에 있지만, production 감각을 바꾸는 차별점이 두 가지 있어요. 첫째, 기본 모드가 완전 로컬·결정론적입니다 — `pip install` 후 `convert(...)` 호출만으로 XY-Cut++ 읽기 순서 패스를 거쳐 재현 가능한 Markdown / HTML / JSON(요소별 bbox 포함) 출력이 나옵니다. LLM도, 네트워크도 없습니다. 둘째, 같은 레이아웃 엔진이 PDF 접근성 자동 태깅(팀 주장으로는 첫 OSS end-to-end Tagged PDF 생성기)도 수행해서, RAG용으로 추출한 구조가 곧 WCAG 식 보정도 만족합니다. 하이브리드 모드를 켜면 OCR(80+ 언어)·수식 추출·차트 설명까지 붙고 — 200-PDF 자체 벤치마크에서 0.907로 1위를 가져갑니다. JSON 출력에 요소별 bounding box가 그대로 들어 있어, 다운스트림 청크가 후처리 레이아웃 추론 없이 source-citation 사각형을 들고 다닐 수 있어요.
기본은 로컬에서 돌리고 싶고, bbox 기반 citation을 공짜로 받고 싶고, RAG 품질 구조와 접근성 태깅 사이에서 둘 중 하나를 고르기 싫을 때.
`pip install opendataloader-pdf` 후 `convert(input='doc.pdf', output_dir='out')` — 결정론 모드는 이게 끝. 스캔본·수식·차트가 섞이면 `opendataloader-pdf-hybrid --port 5002`를 먼저 띄우고 `--hybrid` 플래그로 옵트인.
30 min to wire up

Zhipu AI의 0.9B 파라미터 OCR VLM. 문서 이미지를 구조화된 Markdown·JSON으로 파싱합니다. frontier OCR처럼 모델을 키우는 대신, 레이아웃 검출기와 Multi-Token Prediction을 결합해 OmniDocBench v1.5 1위(94.6)에 오르면서도 엣지에서 돌릴 수 있을 만큼 작게 유지합니다.
GLM-OCR은 복잡한 문서 이해를 위한 멀티모달 OCR 모델로, GLM-V 인코더–디코더 아키텍처 위에 구축되었습니다. 또한 PP-DocLayout-V3 기반의 레이아웃 분석과 병렬 인식 2단계 파이프라인을 결합해, 다양한 문서 레이아웃에서 견고하고 높은 품질의 OCR 성능을 제공합니다. 파라미터는 단 0.9B입니다.
엣지나 고동시성 서비스에 실제 배포 가능한 작은 OCR 모델이 필요할 때 — 결정론적 OCR 작업에 frontier VLM 비용을 더는 내고 싶지 않을 때.
HuggingFace `zai-org/GLM-OCR`에서 받아서 vLLM·SGLang·Ollama 중 하나로 서빙. 가장 빠른 sanity check은 ocr.z.ai 데모 — 와이어링 전에 먼저 찍어보세요.
1-2 hours to deploy

코드, PDF, HTML, 마크다운, 이미지, 영상이 섞인 폴더 위에 바로 얹는 Graph RAG. 벡터 top-k나 grep보다 정확한 retrieval을, chunk 추측 대신 그래프 구조 탐색으로 만들어줍니다.
코드, PDF, HTML, 마크다운, 스크린샷, 영상이 한데 섞인 폴더를 단일 지식 그래프로 묶어주는 Graph RAG 도구. 세 단계로 추출합니다 — ①tree-sitter 기반 결정론적 AST 추출(25개 언어), ②faster-whisper 로컬 오디오 transcription, ③문서·이미지에 대한 병렬 LLM 추출. 클러스터링은 임베딩 없이 Leiden 알고리즘으로 그래프 토폴로지 자체에서 뽑아냅니다. retrieval 측면의 효과는 명확해요 — 에이전트가 raw chunk를 grep하거나 벡터 top-k로 꺼내는 대신, god 노드·커뮤니티·타입드 엣지를 따라 그래프를 traverse합니다. 저자 벤치마크 기준 mixed corpus에서 쿼리당 토큰 71.5배 절감. 나머지 절반의 가치는 PreToolUse 훅에 있어요. Claude Code, Cursor, Codex, Gemini CLI, Copilot CLI, OpenCode, Aider에서 Glob/Grep 호출 직전에 'GRAPH_REPORT.md부터 읽어라'가 자동으로 끼어들어서, 만들어둔 그래프가 장식이 아니라 always-on retrieval substrate가 됩니다.
코드·PDF·문서가 뒤섞인 corpus에서 벡터 RAG나 grep이 자꾸 엉뚱한 chunk를 가져올 때 — 직접 파이프라인 안 깔고 그래프 기반 retrieval로 바로 넘어가고 싶다면.
스킬 설치 → 프로젝트 루트에서 `/graphify .` 실행 → `graphify claude install`(또는 사용 중인 에이전트용 명령어)로 PreToolUse 훅까지 걸어 always-on으로 만드세요.
1 hour setup
ML 전문가로 거듭나기 위한 마지막 10%. 흔히들 예술의 경지에 올랐다고 하잖아요? Hyper-parameter tuning이 그런 영역입니다.
arXiv에 올라온 고인용 논문으로, Random Forest 각 하이퍼파라미터가 예측에 미치는 영향을 체계적으로 분석해줍니다. '그냥 돌렸더니 잘 나왔어요'가 아니라, 모델을 배포 리뷰에서도 당당히 설명하기 위해서는 실제 어떻게 작동하는지 알아야 합니다.
그냥 적용하니까 잘 나왔어요식의 접근을 벗어나 튜닝 선택을 설명하고 싶을 때
먼저 한 번 훑어 직관을 잡고, 실제 모델을 튜닝하면서 각 섹션을 다시 참고하세요.
1 day
상황별로 정리된 22가지 RAG 기법. 언제 어떤 걸 써야 하는지 결정해드립니다.
직접 써보고 잘 작동했던 RAG 기법들을 ①정확한 정보 추출 ②창의적 RAG ③퍼포먼스 사이드 메뉴 ④기피할 기법 네 가지로 분류해둔 레포입니다. Hierarchical indices, Fusion retrieval, Graph RAG, Reranker, Query transformation 등 핵심 기법들을 언제 써야 하는지 명확히 알려줍니다.
Naive RAG를 만들어봤는데 retrieval 품질을 더 높여야 할 때 사용하세요.
내 문제와 맞는 RAG 기법을 하나 골라서, 주 1개씩 기법을 직접 적용해보세요.
4 weeks

구글, 메타, 넷플릭스가 실제 ML을 어떻게 운영하는지 — 500+ 사례가 한 레포에.
Eugene Yan이 정리한 전설의 applied-ML 리스트. 검색, 추천, 이상탐지, 예측 등 문제 유형별로 빅테크의 실제 프로덕션 글을 모아뒀습니다. 문제 정의 → 접근 → 비즈니스 임팩트까지 한 번에 볼 수 있어서, 디테일이 살아있는 창의력을 키우는 데 최고의 자료예요.
새 ML 프로젝트를 스코핑할 때, 비슷한 문제를 남들은 어떻게 프레이밍했는지 보고 싶을 때.
도메인으로 검색해서 3~5개 글을 훑고, 아키텍처가 아닌 프레이밍을 훔쳐오세요.
Reference
ML 개념의 90%를 커버하는 530페이지 레퍼런스 PDF — 처음부터 다 읽지는 마세요.
데이터 전처리부터 모델 배포까지 전체 파이프라인을 다루는 Daily Dose of DS의 방대한 레퍼런스입니다. Section 2부터 시작하는 걸 추천하고, 2.4/2.5/2.7/2.10은 모델 선택 전에, 2.8/2.12/2.15~2.17은 EDA/전처리 때, 2.9/2.13/2.14는 튜닝이 안 풀릴 때 펼쳐보세요.
모르는 개념이 나오거나 모델 행동이 이상할 때 펼쳐보는 레퍼런스로 사용하세요.
Section 2부터. 처음부터 끝까지 읽지 말고, 현재 궁금한 챕터만 뽑아 읽으세요.
2 weeks to skim
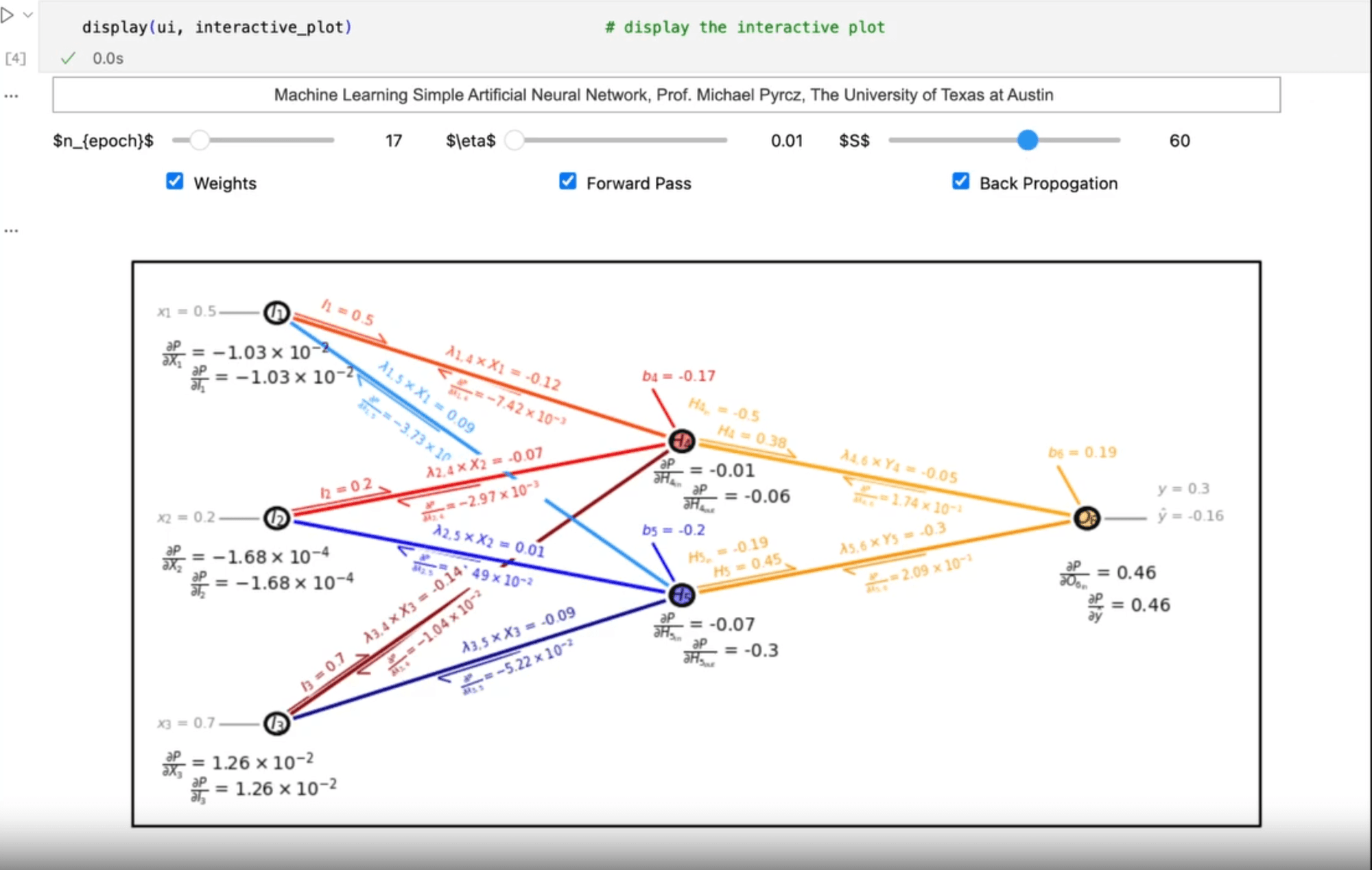
텍사스 주립대 교수의 66가지 인터랙티브 노트북. ML 개념을 전부 시각화로 배우기
Distribution부터 Bagging, PCA, Shapley까지 시각화하기 까다로운 개념들을 전부 시각으로 풀어놓은 repo입니다. 패키지 import가 아니라 numpy와 scipy만으로 알고리즘을 한 줄 한 줄 직접 구현해서, 코드를 뜯어보면 알고리즘의 핵심까지 깨달을 수 있는 일석이조 자료예요.
ML 개념이 추상적으로 느껴지고 움직이는 그림으로 확인하고 싶을 때.
레포를 클론하고 노트북을 직접 실행하면서 numpy 코드도 함께 읽으세요.
4 weeks
읽기만 하지 말고 — PDF 하나 준비해오세요. 모든 기법을 직접 적용해볼 수 있습니다.
22가지 RAG 기법 레포를 '한 달 프로젝트' 방식으로 공부하는 가이드. PDF를 하나 골라 각 기법을 하나씩 적용해보면, RAG 기본은 물론 새로운 아키텍처까지 설계할 수 있는 능력이 생깁니다.
RAG 이론은 충분히 봤고 이제 한 달 집중 빌딩 시간을 갖고 싶을 때.
테스트용 PDF 하나를 정하고, 각 기법을 적용해서 retrieval 품질을 비교하세요.
4 weeks

GitHub 레포나 로컬 코드베이스를 읽기 쉬운 튜토리얼로 변환해주는 툴.
코드베이스를 분석해서 초보자도 이해할 수 있는 문서로 바꿔주는 agent 기반 도구입니다. 낯선 프로젝트를 온보딩할 때도 유용하고, 본인 프로젝트에 documentation 작성이 귀찮을 때도 유용해요.
새 코드베이스에 투입됐거나, 본인 프로젝트 문서화를 미뤄왔을 때.
클론 → 레포를 지정 → 생성된 튜토리얼을 검토 후 정확도 보정하세요.
1 hour setup

매일 트렌딩 논문 + 코드 + 바로 쓸 수 있는 HF 모델이 한 피드에.
Meta의 Papers With Code가 중단되면서 HuggingFace Daily Paper에 흡수됐습니다. 덕분에 '좋아요'와 GitHub ⭐로 트렌딩 논문을 확인하고, 논문 코드 repo를 곧바로 볼 수 있고, 언급된 모델을 HF에서 바로 돌려볼 수 있어요. 데이터 사이언티스트에게 이만한 플랫폼이 없습니다.
AI 연구 흐름을 주 1회씩 체크하고 싶을 때.
트렌딩 목록 훑기 → 논문과 repo 같이 열기 → 모델을 HF에서 바로 테스트.
Reference

DeepSeek 스타일 reasoning model을 직접 만들어볼 수 있는 HuggingFace 실시간 코스.
Reasoning 모델의 훈련 레시피와, 왜 기존 instruction-tuned LLM과 behaviorally 다른지를 HuggingFace가 실시간으로 공개하는 강의. 다른 사람이 만든 모델을 가져다 쓰기만 하기엔 재미 없잖아요.
기본 LLM 훈련은 익숙하고 reasoning 모델 구조를 직접 이해하고 싶을 때.
GPU 환경에서 챕터를 순서대로 따라가며 코드를 직접 실행해보세요.
2 weeks

공개 2주만에 6만 명이 등록한 agent 입문 강의. 무료.
LLM agent 입문에 가장 체계적인 HuggingFace 무료 코스. 완강 후에는 ChatGPT 같은 서비스가 작동하는 원리가 머릿속에 그려지고, 나만의 LLM 서비스를 직접 만들 수 있는 능력이 생깁니다. 깊이보다는 체계적인 시작점으로 최고예요.
Agent를 처음 접하거나, LangGraph/커스텀 프레임워크로 넘어가기 전에 기초를 잡고 싶을 때.
주차별로 챕터 진행 + 작은 개인 agent 프로젝트를 캡스톤으로 만들어보세요.
2 weeks

Sebastian Raschka의 Llama 3.2 from-scratch 구현을 단계별로 따라 읽기.
HuggingFace Spaces에 올라온 Llama 3.2의 깨끗한 from-scratch 구현입니다. 모든 레이어가 읽기 좋은 Python으로 작성돼 있어서, 논문 아키텍처를 실행 가능한 코드로 매핑하며 'why'까지 이해할 수 있어요.
Transformer를 개념적으로 알고 있고, 최신 LLM의 전체 조립을 코드로 보고 싶을 때.
모듈 하나씩 읽고, 스스로 다시 짜본 뒤 원본과 diff를 비교하세요.
2 weeks

Llama from scratch를 영상으로 쭉 설명해주는 YouTube 컴패니언.
코드만 읽기 벅찰 때 같이 보면 좋은 영상 강의. 각 디자인 결정을 말로 풀어주기 때문에, from-scratch 구현을 소화하기 훨씬 수월해집니다.
코드 워크스루의 특정 섹션이 잘 안 잡힐 때 같이 보세요.
20분씩 끊어서 보고, 일시정지해서 방금 본 부분을 직접 구현하세요.
2 weeks

LangChain 공식 LangGraph 입문 — stateful agent로 가는 가장 짧은 길.
LangChain Academy가 만든 무료 LangGraph 코스. 그래프/상태/노드의 핵심 추상화를 짚고 작은 agent 예제를 만들어봅니다. 짧고 집중적이라서 LangGraph를 본격 프로젝트에 적용하기 전 기초로 딱이에요.
간단한 체인을 만들어봤는데 분기/상태 관리의 한계가 느껴질 때.
1주일 안에 코스를 끝내고, 기존 체인 하나를 LangGraph로 다시 짜보세요.
1 week
sklearn만 쓸줄 알고, ML 모델의 내부 작동 방식은 설명 못할 때. 진정한 ML을 위해 꼭 필요한 학습 자료.
Patrick Loeber의 classic ML from-scratch 레포. 선형회귀, 결정트리, k-means 등을 numpy로 직접 구현해둔 코드가 있어서, 대학원에서 시키는 from-scratch 실습을 혼자서도 해볼 수 있어요. 기술면접에서도, 실무 튜닝에서도 무조건 도움이 됩니다.
sklearn은 자유자재로 다루지만 .fit() 내부가 블랙박스처럼 느껴질 때.
레포를 안 보고 각 알고리즘을 직접 구현해보고, 실제 repo의 글과 비교하며 정답을 체크해보는 방식으로 진행
3 weeks
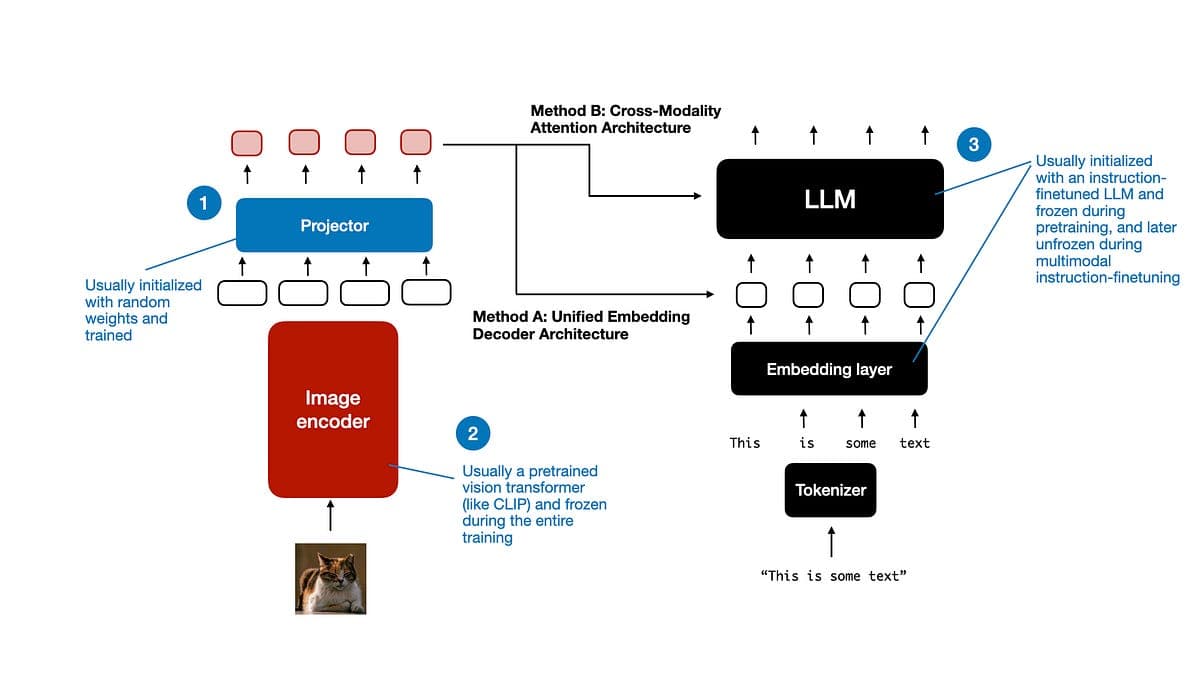
Multimodal LLM이 실제 어떻게 동작하는지 한 번에 정리해주는 아티클.
비전 인코더가 언어 모델과 어떻게 결합되는지, 각 접근법의 장단점, 현재 시스템의 한계까지 한 번에 정리해주는 글. 복잡한 주제를 시원하게 설명해주는 글이에요.
Multimodal 모델을 tuning하기 전에 반드시 읽으세요 — 몇 시간의 삽질을 아낄 수 있어요.
한 번에 쭉 읽고, 세부 아키텍처로 들어가보세요.
1 day

Transformer가 뭔지 안다를 넘어서, 직접 작성할 수 있도록 처음부터 끝까지 가이드를 제공해주는 책.
NLP 사전 지식 없이도 LLM을 순수 Python으로 구현해볼 수 있게 이끌어주는 종합서. 끝까지 이해하면 NLP 준전문가가 됩니다. 두 달만 투자해보세요 — LLM 시대에 든든한 보물 창고가 생길 거예요.
특정 프레임워크에 묶이지 않는 LLM 기본기를 만들고 싶을 때.
순서대로 읽고, 모든 예제 코딩 + 모든 연습문제 풀기. 두 달 집중 투자.
8 weeks

프레임워크 없이 직접 NN을 작성하는 YouTube 코스 — 최신 아키텍처를 이해하는 뿌리가 됩니다.
직접 뉴럴네트워크를 작성해보는 실습 영상. Transformer든 mamba든 새로운 아키텍처가 나와도, '이건 내가 짠 기본 NN의 변형이구나'로 받아들일 수 있게 기본기를 만들어줍니다.
backprop이 그냥 알아서 되는 것이라는 말로 넘어가던 본인이 답답해질 때.
영상을 틀고 같이 코딩하세요. 그냥 보기 금지. 애매한 스텝은 일시정지 후 다시 유도.
3 weeks
LangChain 없이도 LLM에서 structured output을 뽑아내는 경량 패키지.
Pydantic/regex/JSON 스키마로 LLM 출력을 제약해주는 라이브러리. LangChain 같은 무거운 프레임워크의 dependency 없이 개발하고 싶을 때 이 하나로 해결됩니다. 백엔드 모델도 자유롭게 교체 가능.
신뢰할 수 있는 JSON 출력이 필요한데 프레임워크 종속은 피하고 싶을 때.
Pydantic 모델 정의 → Outlines에 전달 → 필요에 따라 LLM 백엔드 교체.
1 day

Python logging 모듈의 복잡한 보일러플레이트를 한 줄 import로 끝내는 드롭인 대체재.
구조화된 출력, 로테이션, 비동기 안전 핸들러, 합리적인 기본값까지 — Loguru 하나로 해결됩니다. 프로덕션을 지향하는 Python 프로젝트라면 가장 먼저 추가할 라이브러리.
Python 프로젝트에서 프로덕션에서 뭐가 잘못됐는지 알고 싶어지는 순간.
pip install loguru → logging import 교체 → 배포. 로테이션은 필요할 때 설정.
30 minutes
Multimodal 파싱 + Graph RAG까지 제대로 구현된 end-to-end RAG 시스템.
PDF, Word, 이미지까지 MinerU 기반 OCR로 처리하고, 이미지에는 설명을 생성해서 분석 가능하게 만들어주며, Graph RAG로 계층적 retrieval 성능을 극대화한 패키지입니다. 매번 비슷한 RAG 파이프라인을 반복해서 만드는 게 지겨워진 분들에게.
프로젝트마다 똑같은 RAG 파이프라인을 다시 만드는 게 지겨워졌을 때.
내 문서를 넣어서 retrieval set으로 평가하고, 기본값이 부족한 부분만 커스터마이즈.
1 day setup
Reasoning 모델이 기존 LLM과 무엇이 다른지를 시각으로 차근차근 알려주는 가이드.
Maarten Grootendorst의 시각 가이드. LLM 기본 구조부터 시작해서 O1/O3, R1 같은 reasoning 모델이 왜 behaviorally 다른지까지 올라갑니다. DeepSeek 논문을 읽기 전의 첫 정류장으로 최고.
R1 논문을 읽기 전, 혹은 나만의 reasoning 모델 빌딩에 뛰어들기 전에.
쭉 읽고, 본문에 나오는 키워드를 따라 더 깊은 논문으로 탐색.
1 week

Stanford 2025년 LLM 강의 전체 녹화본이 YouTube에 올라와 있습니다.
토크나이저부터 아키텍처, 스케일링, 얼라인먼트까지 LLM 스택 전체를 직접 만드는 사람들의 관점에서 풀어주는 코스. 온라인 강의들 중 가장 밀도 높고, 사이드 프로젝트와 병행하면 무료로 받을 수 있는 'LLM 도제 수업'에 가장 가깝습니다.
현대 LLM 훈련의 가장 깊은 개념 지도를 원할 때.
강의 하나씩 천천히 보면서 수식은 직접 유도 + 주 1과제 최소 구현.
4 weeks

시각화의 대가 Grant Sanderson의 1시간짜리 transformer 영상.
Embedding vector부터 self-attention까지 Transformer의 전 과정을 시각적으로 풀어주는 3Blue1Brown 영상. LLM 공부를 시작하기 전에 한 번 보면, 이후 배우는 모든 개념이 머릿속에 훨씬 선명하게 그려집니다.
Transformer를 공부하기 전 첫 리소스로 추천. 이후 모든 공부가 빨라집니다.
한 번 쭉 시청 → 이후 논문 읽을 때 섹션 단위로 다시 돌려보기.
1 week

HuggingFace의 nanoVLM — 머릿속에 들어올 만큼 작고 읽기 쉬운 VLM 구현.
HuggingFace가 공개한 최소한의 VLM 레퍼런스. ①Raschka의 multimodal essay ②HF VLM 블로그 ③nanoVLM 코드 ④Colab 실행 순서로 따라가면, 작은 vision-language 모델을 실제로 학습시킬 수 있게 됩니다.
Multimodal LLM을 개념적으로 이해했고, 이제 직접 만들어보고 싶을 때.
추천 아티클을 먼저 읽고 → nanoVLM 코드를 한 줄씩 → Colab에서 실행까지.
4 weeks
웹 개발자용이 아니라 AI 모델 개발자용 — Cursor 친화 프로젝트 구조.
대부분의 프로젝트 템플릿은 웹용. 이 레포는 정확히 AI/ML 프로젝트를 위한 구조 + Cursor rule 세트입니다. 포크해서 프로젝트 시작을 빠르게 잡고, 그 후 원하는 방향으로 조금씩 바꿔가면 Cursor도 인식하기 쉬워져요.
새 AI 프로젝트 폴더 구조를 지난주 프로젝트를 복사하는 걸로 때우는 게 싫어질 때.
Fork → 이름 변경 → 도메인에 맞게 Cursor rule을 조정.
1 hour setup

'ML 모델은 블랙박스'가 아니라는 것을 증명해내고 실제 비즈니스 케이스에 적용하고 싶을 때
SHAP, LIME, Partial Dependence, Permutation Importance 등 해석 가능성 기법을 모델에 적용하는 방법 소개합니다. 이 책을 한 번 읽으면 '모델이 그냥 그렇게 판단했어요'가 아니라, 실제 문제를 해결 할 수 있는 형태로 모델을 만들 수 있습니다.
'왜 이렇게 예측했나'를 구체적으로 설명이 필요할 때.
챕터 하나당 일주일. 각 방법을 이미 학습한 모델에 적용해보세요.
4 weeks

하루짜리 Zero-shot image classification 실습. 실무에서 바로 씁니다.
HuggingFace의 공식 zero-shot inference 가이드. 분량은 작지만 밀도는 높아서, zero-shot이 실무에서 무엇을 의미하는지와 내 파이프라인에 어떻게 붙이는지를 한 번에 잡을 수 있어요.
학습 데이터 없이 뭔가를 분류해야 하는 첫 순간에.
예제를 노트북에서 돌리고 → 내 라벨과 내 이미지로 바꿔 테스트.
1 day
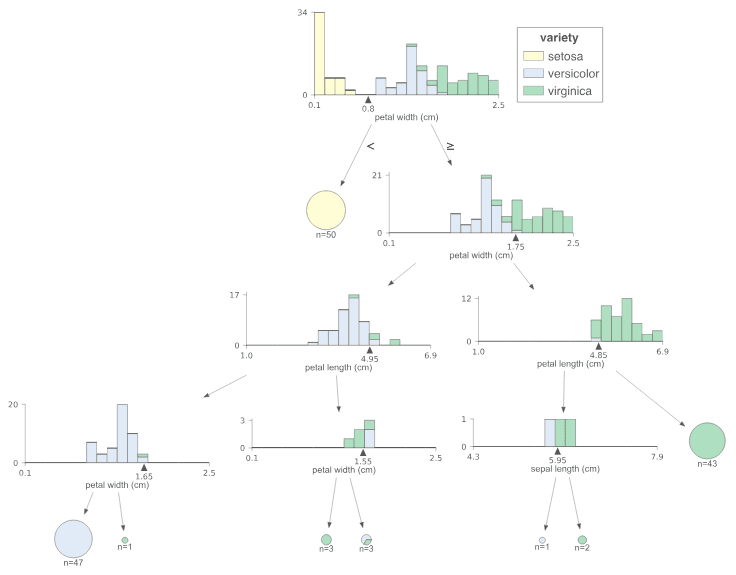
트리 모델의 학습 경로, 각 노드 데이터, 예측 경로까지 전부 시각화.
D3 기반 decision tree 시각화 패키지. 각 노드의 data distribution, leaf purity, overfit/underfit 시그널, 새 데이터의 prediction 경로까지 전부 보여줍니다. scikit-learn, XGBoost, LightGBM, Spark MLlib, TensorFlow와 호환돼요.
트리 모델의 특정 예측이 왜 그렇게 나왔는지 설명해야 할 때.
pip install dtreeviz → 학습된 모델 전달 → HTML로 export.
1 hour
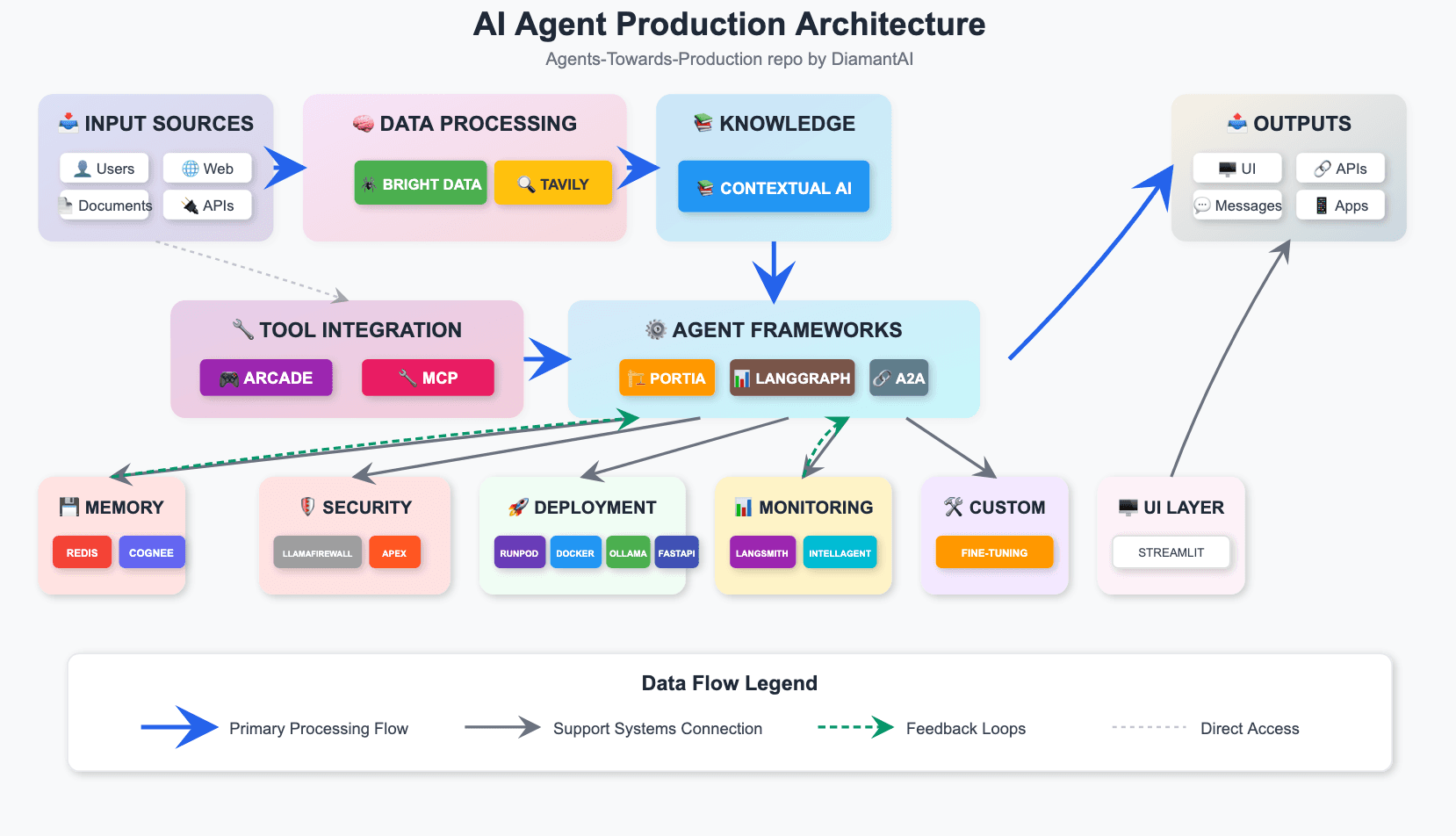
AI 엔지니어의 70%가 어려워하는 영역 — 데모를 진짜 서비스로 만들기.
AI 엔지니어의 70%가 본인의 AI 모델을 배포하는 데 어려움을 겪는다고 합니다. '실제 작동하는' AI 서비스를 만들려면 단순히 RAG 아키텍처를 짜는 것만으로는 부족하더라고요. LLM이 특정 답변만 내놓도록 막아주는 guardrailing, 성능과 비용을 추적하는 모니터링, 모듈 간 깔끔한 통신을 위한 FastAPI 모듈화, 그리고 실제 배포를 위한 Docker — 거기에 토이 프로젝트와는 다른 long-term memory까지 — 이 모든 걸 한 자리에 모아놓은 레포입니다.
내 LLM 데모를 진짜 서비스로 만들고 싶은 순간 바로.
모듈을 하나씩 따라가면서 내 agent를 실제로 배포하는 걸 병행하세요.
4 weeks

GURU로부터 배우는 time series — 13챕터짜리 무료 교과서.
Hyndman의 무료 시계열 책(R 기반). Decomposition, ARIMA, ETS, 계층적 forecasting, ML 하이브리드까지 다룹니다. 시계열에서는 아직 R이 Python보다 앞서 있어서, Python 유저라도 이 책을 보면 시계열 감각이 훨씬 날카로워져요.
'lag 줘서 XGBoost에 넣으면 되지'가 더 이상 안 통하는 순간.
하루 한 챕터씩 13일. 내가 관심 있는 데이터셋에 각 방법을 직접 적용.
4 weeks

2019년 화이트보드 강의 — Old but gold. 요즘의 얄팍한 강의보다 훨씬 잘 설명합니다.
교수님이 화이트보드에 직접 수식을 쓰면서 설명. 유행어 없이 핵심만 담겨 있어요. 하나의 뉴런이 무슨 기능을 하는지, activation function, feed forward, word embedding, Transformer의 self-attention까지 — 기본기 중의 기본기를 단단히 잡아줍니다.
요즘 유행 강의에서 '뉴런이 실제 뭘 하는가'가 손에 안 잡힐 때.
순서대로 시청 + 각 유도를 손으로 직접 써보세요.
3 weeks