데이터 사이언스
리소스 모음집
모든 최신 정보를 따라갈 필요는 없습니다. 정말 유용한 리소스는 시간이 지나도 살아남고, 시간은 결국 무엇이 실제로 도움이 되는지를 증명해줍니다. 그래서 빠르게 소비되는 정보가 아니라, 실제 도움이 되는 리소스만 직접 골라 담았습니다.
추천 리소스
전체 보기 →
Second Brain — 개인의 Taste가 쌓이는 지속 가능한 Wiki
Claude Code가 돌리는 셀프호스팅 개인 위키. URL만 붙이면 그 뒤 수집이 자동화되고, `/ingest`가 날것의 메모를 서로 연결된 작은 노트로 정리하고, LanceDB 벡터 색인이 전체를 검색 가능하게 만들고, `/brief`는 관련 노트와 그 연결관계까지 모아 내가 수집해온 방향을 닮은 초안을 써줍니다.
Second Brain — 개인의 Taste가 쌓이는 지속 가능한 Wiki
Github누구나 개인 위키를 만들 순 있지만, 100개·1000개의 노트가 쌓여도 무너지지 않으려면 방법이 정해져 있어요. 의지가 아니라 두 가지 마찰을 없애는 거예요 — 수집의 번거로움, 그리고 '정리'의 비용. Second Brain(Slow AI)은 둘 다 Claude Code에 맡깁니다. [편의성] 수집은 무조건 3초컷이어야 해요. 저장하고 싶은 URL을 `/jina-capture`에 던지면 깔끔한 마크다운으로 `wiki/raw/`에 저장됩니다. 무엇을 모으느냐가 당신의 taste를 결정짓는 첫 단계예요. 더 중요한 건 가장 공수가 큰 부분을 제거하는 것 — 새 노트가 기존 수백 개의 노트와 어떻게 연결되는지를 `/ingest`가 raw를 읽고 알아서 연결된 노트로 만들어 줍니다. [확장 가능성] 이걸 지속 가능하게 받쳐주는 숨은 기능이 둘 있어요. 하나는 Zettelkasten처럼 노트를 작은 개념으로 잘게 쪼개는 것 — 한 노트에 개념이 다섯 개 엉켜 있으면 깔끔하게 연결되기 힘드니까요. 다른 하나는 LanceDB 벡터 저장소, 즉 개인 위키 전용 RAG로 관련 자료를 기억에 의존하지 않고 자동으로 찾아내는 것. [그래서] 보상은 `/brief`예요. 주제만 던지면 관련 노트뿐 아니라 느슨하게 연결된 이웃 노트까지 모아 초안을 만들어, 단일 출처 요약이 아니라 내가 그동안 축적해온 방향성을 닮은 글이 나옵니다. 무엇을 모았고 어떻게 엮었는지가 곧 개인의 taste가 되는 거죠.
링크와 메모를 계속 저장하지만 다시 안 들춰보는 더미로 썩어갈 때, 그리고 노트가 늘수록 더 감당 안 되는 게 아니라 더 촘촘히 연결되는 위키를 원할 때. Claude Code를 이미 쓰고 있다면 best — 턴키 GUI 앱을 원하면 덜 맞아요. 로컬에서 직접 돌리는 레포입니다.
세팅이 제일 쉬워요 — 따라 할 단계 같은 거 없습니다. 레포 URL을 Claude Code에 보내고 "이걸 내 디렉터리에 구현해줘"라고만 하면 알아서 프로젝트를 깔아줘요. 그 뒤로는 전부 슬래시 명령어로 씁니다. `/jina-capture <url>`로 수집, `/ingest`로 raw를 연결된 노트로 정리, `/ask`로 노트 질의, `/brief <주제>`로 문서 초안, `/garden`으로 주간 정리.
~30 min to set up, then seconds per capture

Text-to-Lottie — Claude Code·Codex로 실전용 Lottie 애니메이션 만들기
자연어 프롬프트를 바로 쓸 수 있는 Lottie 애니메이션으로 바꿔주는 오픈소스 스킬. 움직임을 말로 설명하고 SVG를 가리키면 에이전트가 Lottie JSON을 써주고 — 내장 플레이어로 타임라인을 넘기고 속성을 만지고 내보내기까지, After Effects 없이 끝납니다.
Text-to-Lottie — Claude Code·Codex로 실전용 Lottie 애니메이션 만들기
GithubLottie는 벡터 애니메이션을 웹·iOS·안드로이드·React Native·Flutter로 내보내는 표준 포맷이지만, 만들려면 보통 After Effects에 Bodymovin 플러그인을 붙이거나 빽빽한 JSON 키프레임을 손으로 고쳐야 했어요. Text-to-Lottie(Diffusion Studio)는 그 작업을 코딩 에이전트로 우회시킵니다. 스킬로 설치(`npx skills add diffusionstudio/lottie`)한 뒤 Claude Code나 Codex에 평범한 말로 — '이 로고를 펄스로, ease-in-out, 반복' — SVG나 스크린샷, 실제 데이터를 소스로 가리키며 프롬프트하면 됩니다. 에이전트가 Lottie JSON을 뱉고, 함께 들어 있는 플레이어가 그걸 실시간으로 렌더링해서 타임라인을 스크럽하고 노출된 컨트롤(로고 색, 선 두께, 기본 배경색)을 미리보기 안에서 바로 조정할 수 있어요. 결과물은 앱에 그대로 떨어뜨리거나 After Effects에서 마지막 손질을 할 수 있는 순수 `.lottie`/JSON입니다. 흥미로운 지점은 모션 디자인을 '손으로 키프레임 찍는 것'이 아니라 '에이전트가 쓰고 내가 검수하는 것'으로 다룬다는 거예요 — 플레이어가 그걸 정직하게 잡아줍니다. JSON이 아니라 실제 움직임을 보게 되니까요.
웹이나 모바일 UI에 쓸 Lottie 애니메이션이 필요한데 After Effects는 열기 싫을 때 — 또는 SVG 로고가 있고 어떤 움직임을 원하는지 분명해서 애니메이션과 내보내기만 맡기고 싶을 때. 복잡한 캐릭터 애니메이션이나, 처음부터 프레임 단위로 손수 제어해야 하는 작업에는 덜 맞습니다.
`npx skills add diffusionstudio/lottie`로 스킬을 설치한 뒤, 에이전트(Claude Code·Codex)에 애니메이션을 설명하고 SVG·스크린샷·데이터를 가리키며 프롬프트하세요. 'ease-in-out' 같은 모션 용어를 쓰고, 길이·fps를 지정하고, 기본 배경색 외에 원하는 커스텀 컨트롤이 있으면 명시적으로 요청하세요. 내장 플레이어에서 미리보고 다듬은 뒤 JSON을 내보내거나, After Effects에서 마저 손질하면 됩니다.
minutes to install, an hour to dial in one animation
diff-pdf — 두 PDF가 정확히 뭐가 다른지 눈으로 보기
두 PDF를 사람 눈으로 보듯 페이지별로 비교해요. 한 파일을 다른 파일 위에 겹쳐 놓고 달라 보이는 부분을 표시해주니, 뭐가 바뀌었는지 한눈에 잡힙니다.
diff-pdf — 두 PDF가 정확히 뭐가 다른지 눈으로 보기
Githubdiff-pdf가 답하는 질문은 하나예요. 이 두 PDF가 똑같아 보이나요? 속의 텍스트를 비교하는 게 아니라, 화면에 실제로 보이는 모습을 비교합니다. 두 파일을 페이지별로 나란히 맞춰 겹친 뒤, 일치하지 않는 자리를 전부 표시해줘요. 그래서 줄이 밀렸거나, 그림이 바뀌었거나, 글꼴이 다르게 찍힌 부분이 바로 눈에 띕니다. '뭔가 바뀌었나?' 싶은 순간에 딱이에요. 보고서를 다시 뽑았거나, 인보이스를 재출력했거나, 문서를 만드는 도구를 업그레이드한 뒤에 새 버전이 예전과 똑같아 보이는지 확인하고 싶을 때요. 작고 무료인(GPL-2.0) 명령줄 도구이고, PDF 내용을 읽거나 이해하지는 않아요. 그저 각 페이지가 만들어내는 '그림'을 비교할 뿐입니다.
두 PDF가 똑같아 보이는지 확인해야 할 때. 다시 만든 문서가 원본과 여전히 일치하는지 확인하거나, 버전 사이에 생긴 의도치 않은 레이아웃 변화를 잡아내거나, 도구를 업그레이드한 뒤 출력이 조용히 바뀌지 않았는지 점검할 때요. PDF에서 텍스트나 데이터를 뽑아내는 도구는 아닙니다. 페이지를 내용이 아니라 그림으로 보거든요.
두 파일을 넘기면 끝 — `diff-pdf old.pdf new.pdf` — 다른지 아닌지 알려줘요. 옵션을 붙이면 바뀐 부분을 표시한 PDF로 저장하거나, 좌우로 나란히 띄워 한 장씩 넘기며 직접 차이를 볼 수도 있습니다. 문서를 다시 만드는 작업의 마지막 점검 단계로 쓰기 좋아요.
minutes to install and run
COLLEAGUE.SKILL — 동료를 설치 가능한 에이전트 스킬로 병에 담기
전문가가 떠나면 수년치 맥락도 같이 사라지죠. COLLEAGUE.SKILL은 그 사람의 실제 업무 흔적 — 채팅·문서·이메일 — 을 버전 관리되는 스킬 패키지로 증류해 AI 에이전트에 설치합니다.
COLLEAGUE.SKILL — 동료를 설치 가능한 에이전트 스킬로 병에 담기
Github보통 AI 에이전트는 당신이 프롬프트로 알려준 것만 압니다. COLLEAGUE.SKILL(상하이 AI Lab)은 한 사람이 쌓아온 업무 — 채팅 로그, 설계 문서, 이메일, 심지어 회의 자막까지 — 를 에이전트가 실행할 수 있는 설치형 스킬로 바꿉니다. 출력을 일부러 두 층으로 나눠요. 역량 층은 그 사람이 문제를 풀어가는 방식, 즉 사고 모델과 판단 기준이고, 행동 층은 말투와 지켜야 할 선입니다. '판단'과 '말투'를 분리해서, 톤은 복제하지 않고 사고만 빌려오거나 그 반대도 됩니다. 패키지는 블랙박스가 아니에요. 직접 열어 읽고, 자연어로 고치고, 코드처럼 버전을 되돌리고, Claude Code·Codex·Hermes에 두루 설치합니다. 핵심 베팅은 전문성의 이동 단위가 '스킬'이고 에이전트 호스트는 갈아 끼울 수 있다는 것.
핵심 인물이 떠나려 하거나 이미 떠났고, 그 판단이 깔끔한 문서가 아니라 흩어진 흔적 속에 남아 있을 때. 또 누군가의 사고는 빌리되 말투는 따라 하고 싶지 않을 때. 증류할 실제 흔적 자체가 없다면 효용은 떨어집니다.
채팅 로그·설계 문서·이메일·자막 같은 원시 흔적을 연결하면 스킬 패키지가 생성됩니다. 뭘 뽑아냈는지 직접 살펴보고, 자연어로 고친 뒤, 쓰는 에이전트 호스트에 설치하세요. 알아둘 점 하나 — 동료의 행동을 동의 없이 증류하는 건 이 프로젝트가 일으킨 논란의 지점이기도 합니다.
an afternoon to distill and install one skill
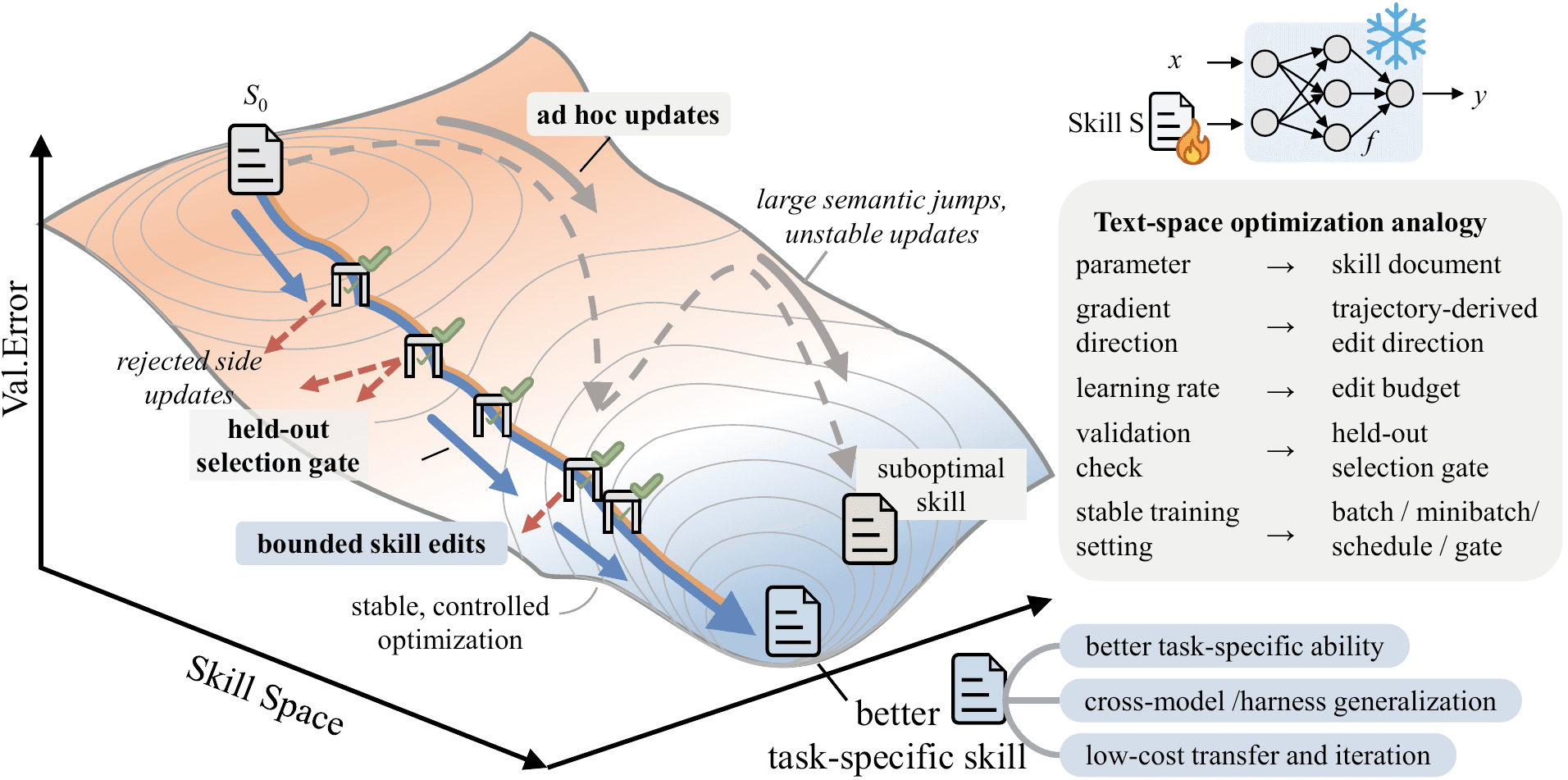
SkillOpt — 스킬 문서를 신경망처럼 훈련하기 (Microsoft)
모델을 다시 학습시키지 않고 AI 에이전트를 똑똑하게. SkillOpt는 모델 대신 '설명서' 한 장을 훈련하고, 시험 점수가 실제로 오른 수정만 남겨요.
SkillOpt — 스킬 문서를 신경망처럼 훈련하기 (Microsoft)
Github보통은 프롬프트를 손으로 고치며 감으로 개선하죠. SkillOpt는 그 과정을 자동화해요. 에이전트가 일을 해보면 별도의 '옵티마이저' 모델이 뭐가 통하고 뭐가 안 통했는지 보고, 스킬 문서의 문장을 추가·삭제·수정합니다. 핵심은 이거예요. 따로 떼어둔 데이터에서 점수가 실제로 올라야만 그 수정을 채택해서, 글이 엉뚱하게 흘러가지 않고 한 걸음씩 좋아집니다. 모델도 에이전트도 그대로고 바뀌는 건 텍스트뿐이라, 실제로 돌릴 때 추가 비용이 없어요. 정답이 분명한 작업(QA·수학·코드)에 가장 잘 맞아요.
모델은 다시 못 바꾸는데 정답을 객관적으로 채점할 수 있는 작업에서, 정확도를 공짜로 더 끌어올리고 싶을 때. 글쓰기 같은 주관적 작업에는 믿을 만한 채점기부터 만들 수 있을 때만.
`pip install skillopt` 후 내 작업에 연결하면 끝. 진짜 할 일은 라이브러리가 아니라, '이 수정이 정말 좋아진 건지' 판정할 시험(채점 기준)을 만드는 거예요.
a weekend to run a benchmark

LangExtract — 소스 근거를 보장하는 LLM 정보 추출 라이브러리 (Google)
Google이 유지보수하는 Python 라이브러리. LLM으로 비정형 텍스트에서 구조화된 필드를 뽑아냅니다. 모델이 위치를 환각하도록 두는 대신, 모든 추출을 원본의 정확한 문자 구간으로 매핑해서 — 신뢰가 아니라 검증·하이라이트·감사가 가능한 결과를 돌려줍니다.
LangExtract — 소스 근거를 보장하는 LLM 정보 추출 라이브러리 (Google)
GithubLangExtract는 문서에서 필요한 정보를 구조화해 추출하고, 원본 텍스트의 정확한 위치에 매핑해 인터랙티브 HTML로 시각화하는 패키지입니다. 이 패키지가 성공한 이유는 사람들의 '불안 심리'를 잘 이용했기 때문이에요. 우리도 GPT가 결과를 어디에서 가져왔는지 알려주지 않으면 '진짜 맞나?' 하며 의심부터 하게 되잖아요. 그래서 어떤 정보를 추출할지 미리 정의해 주면, LLM이 관련 정보를 추출하고 — 그것들이 어디에서 나왔는지 그 근거와 함께 — 시각화까지 해 줍니다.
추출 파이프라인이 자꾸 '거의' 맞는 필드만 뽑아내고, 모든 값에 검증 가능한 영수증 — 원본의 정확한 문자 오프셋 — 이 필요할 때.
`pip install langextract` 후, 추출 지시문과 few-shot 예시를 정의하고 `lx.extract(text=..., prompt_description=..., examples=...)`를 Gemini·OpenAI·Ollama 모델 ID와 함께 호출. 결과는 `lx.visualize(...)`로 인터랙티브 HTML 뷰어를 띄워 소스 하이라이트와 함께 검토.
1 hour to wire up